| Abstract
Tool-augmented vision–language models (VLMs) can solve multimodal, multi-step tasks by calling external tools, yet they remain fragile in practice. Existing training has two common gaps: supervised fine-tuning (SFT) is built mostly on successful trajectories and offers little signal for recovery after tool failures, while sparse trajectory-level RL rewards provide limited guidance on which step failed and how to repair it.
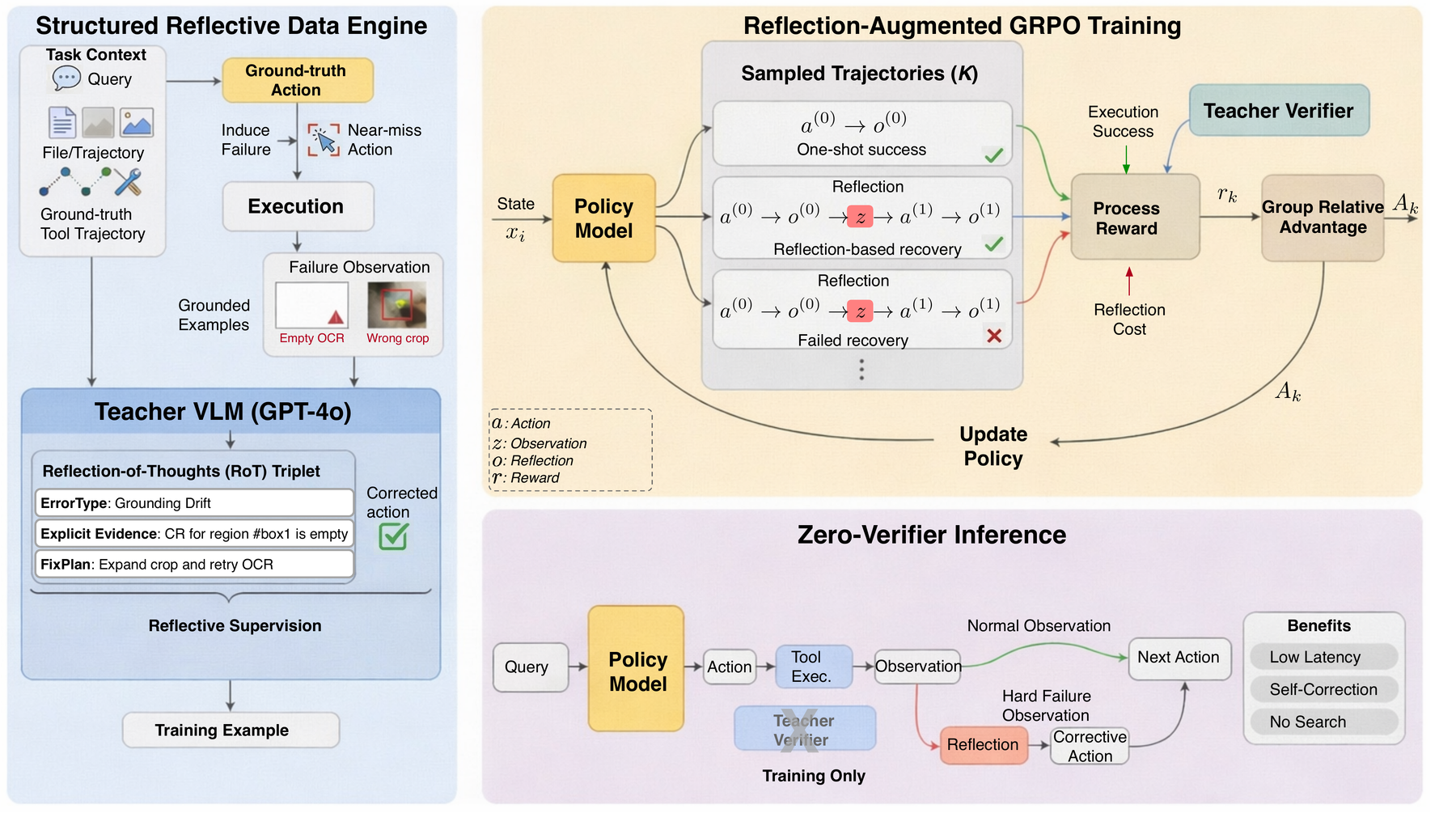
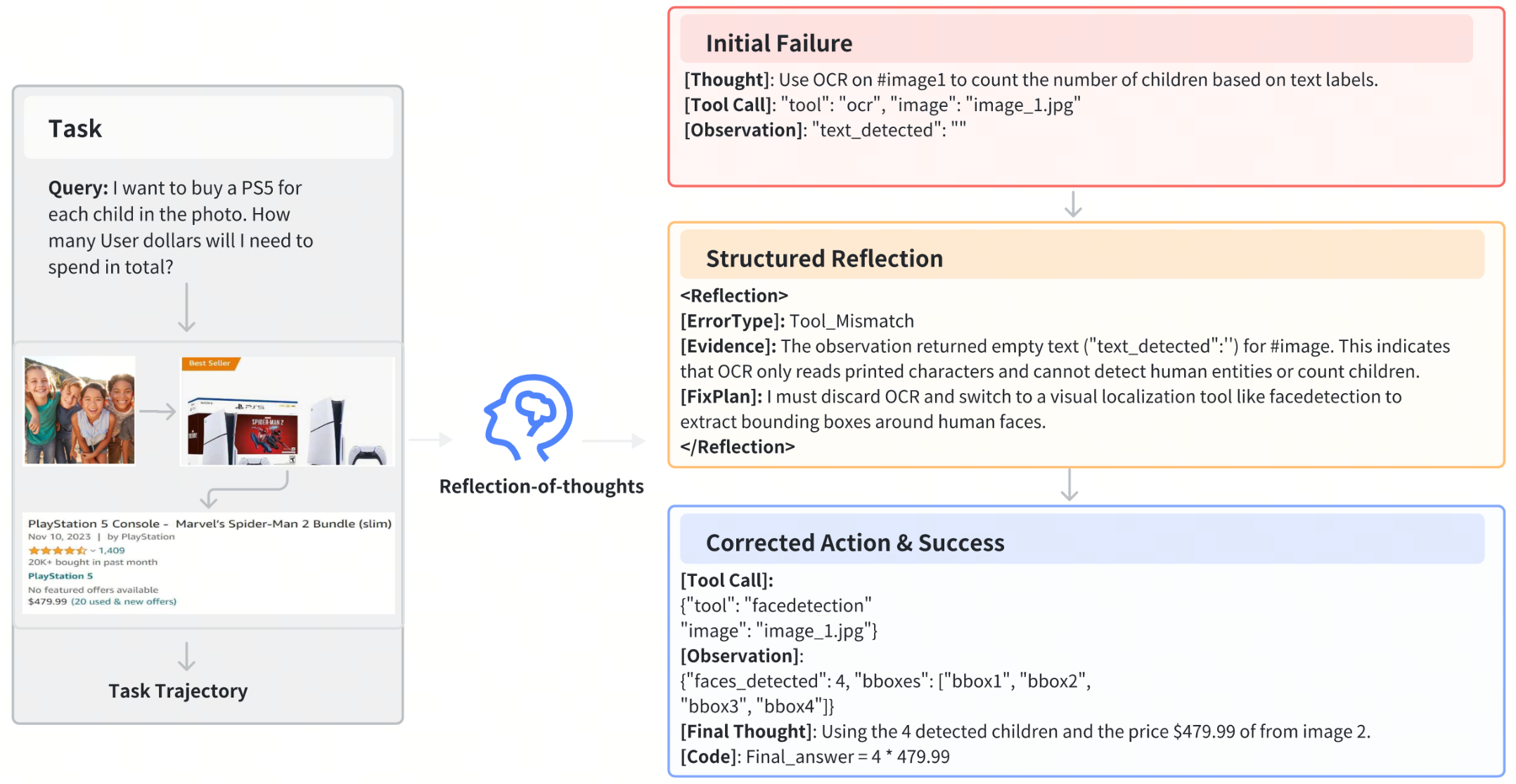
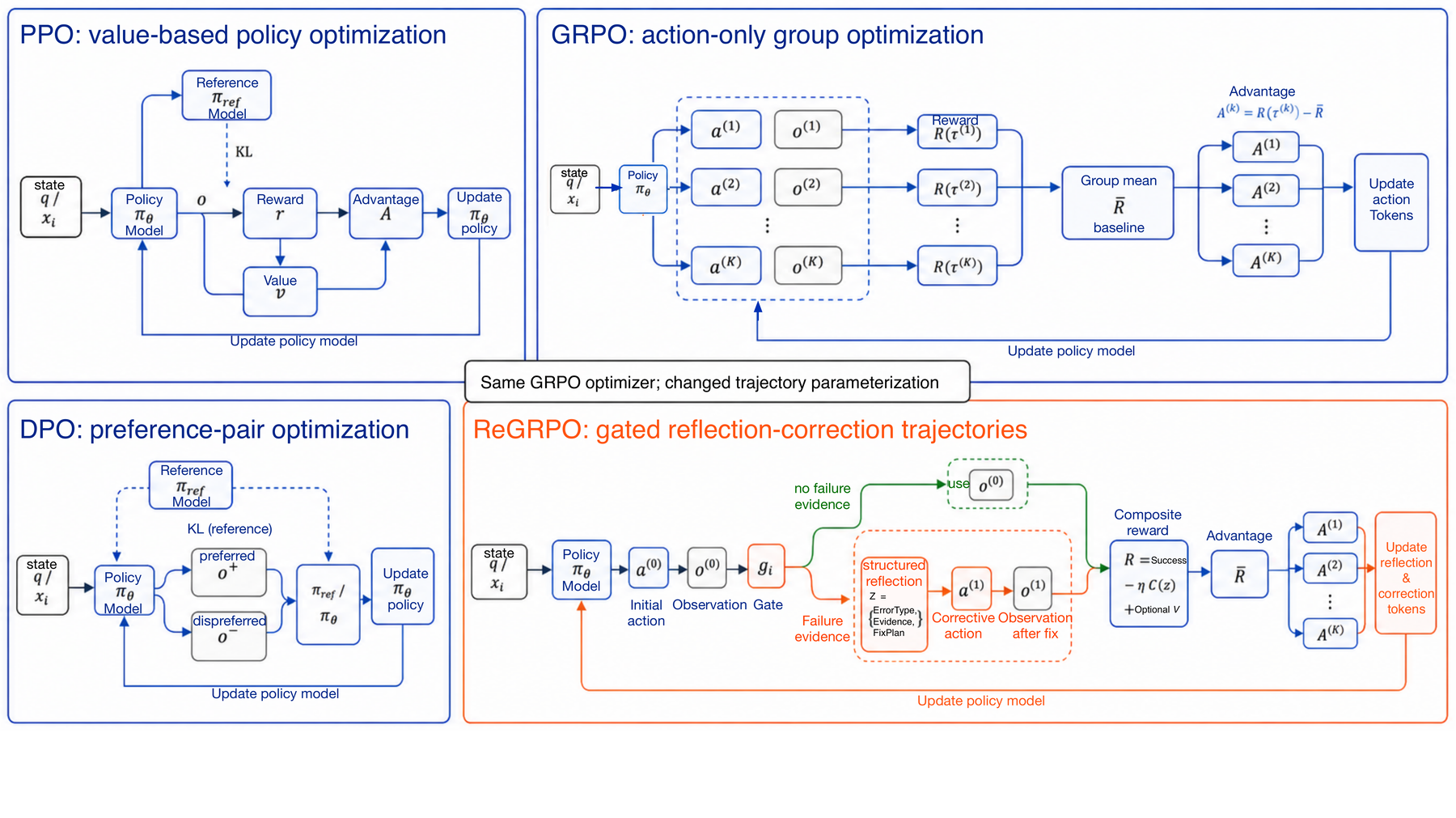
We introduce ReGRPO (Reflection-augmented Group Relative Policy Optimization), a framework that learns reflection-guided correction in tool-using agents. ReGRPO starts with a structured reflective data engine: we execute near-miss actions to collect grounded failure observations, then build Reflection-of-Thought triplets (ErrorType, Evidence, FixPlan) paired with corrected actions for warm-start SFT. We then optimize reflection tokens and corrective actions jointly within local trajectories using group-relative advantages, and include a reflection-cost term to reduce unnecessary reflection. Experiments on GTA and GAIA show that, under the same backbone and tool suite, ReGRPO consistently outperforms strong open-source baselines and achieves the best results among the compared open-source controllers.